Abstract
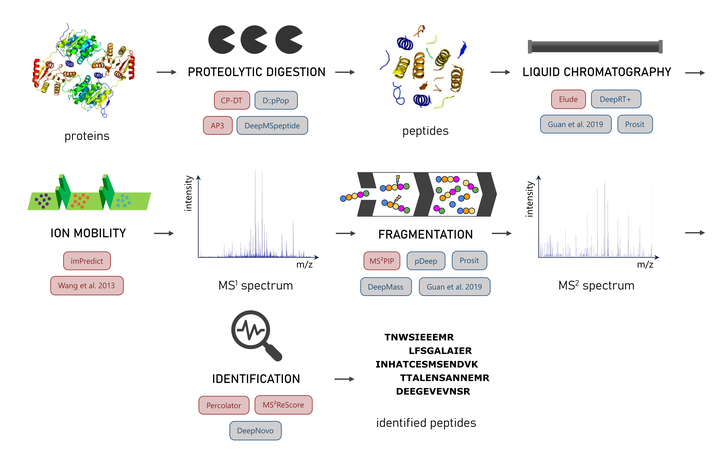
A lot of energy in the field of proteomics is dedicated to the application of challenging experimental workflows, which include metaproteomics, proteogenomics, data independent acquisition (DIA), non-specific proteolysis, immunopeptidomics, and open modification searches. These workflows are all challenging because of ambiguity in the identification stage; they either expand the search space and thus increase the ambiguity of identifications, or, in the case of DIA, they generate data that is inherently more ambiguous. In this context, machine learning-based predictive models are now generating considerable excitement in the field of proteomics because these predictive models hold great potential to drastically reduce the ambiguity in the identification process of the above-mentioned workflows. Indeed, the field has already produced classical machine learning and deep learning models to predict almost every aspect of a liquid chromatography-mass spectrometry (LC-MS) experiment. Yet despite all the excitement, thorough integration of predictive models in these challenging LC-MS workflows is still limited, and further improvements to the modeling and validation procedures can still be made. In this viewpoint we therefore point out highly promising recent machine learning developments in proteomics, alongside some of the remaining challenges.